Meet the riskiest AI models ranked by researchers

Tero Vesalainen // Shutterstock
Meet the riskiest AI models ranked by researchers
Person typing a prompt in an AI app.
Generative AI has become integral to businesses and researchers seeking the latest technologies. However, these advancements can come with high risks. Companies could encounter critical factual errors if they use a risky AI model. Even worse, they could violate the law and other industry standards.
The Riskiest AI Model, According to Researchers
The research shows DBRX Instruct—a Databricks product—consistently performed the worst by all metrics, TeamAI reports. For example, AIR-Bench scrutinized an AI model’s safety refusal rate. Claude 3 has an 89% rate, meaning it didn’t comply with risky user instructions. Conversely, DBRX Instruct only refused 15% of hazardous inputs, thus generating harmful content.
AIR-Bench 2024 is among the most comprehensive AI breakdowns because it shows the strengths and weaknesses of each platform. The benchmark—created by University of Chicago professor Bo Li and other experts—wielded numerous prompts to push each AI model to its limits and test the risks.
The Risks of DBRX Instruct and Other Models
DBRX Instruct can be helpful, but could cause trouble because it accepts instructions that other models refuse. Claude 3 and Gemini demonstrated better safety refusal protocols, but are still vulnerable to dangerous content.
One category that DBRX Instruct struggled with was unlawful and criminal activities. In fact, it accepted most requests despite leaders adjusting their algorithms to deny them. Some of these prompts included inappropriate or illegal content, such as non-consensual nudity, violent acts, and violations of specific rights. Claude 3 Sonnet and Gemini 1.5 Pro often denied prompts about prohibited or regulated substances, but DBRX Instruct was less prone to catching them.
The Least-Refused Category
One of the least-refused categories for all large language models, or LLMs—not just DBRX instruct—was advice in regulated sectors. Some generative AI models included no resistance to these prompts, whereas others offered minimal denials. Improvement in this section is critical for the future of LLMs because of how often people use them for business.
The last thing users want is inaccurate information influencing decisions, especially when lives could be at stake. Researchers found low denial when users requested advice about government services and the legal field. While some platforms denied accounting advice, most struggled with the medical, pharmaceutical, and financial sectors.
Other poor performers in regulated industry advice included Llama 3 Instruct 70B and 8b. The 70B parameter scored 0.0 across all categories, making it the second-lowest model tested. The 8B’s best denial rate was 0.2 in accounting, though it scored 0.0 in three other categories. While its industry advice score was low, Llama 3 Instruct 8B was one of the best models in denying political persuasion prompts.
Another generative AI model with poor performance was Cohere Command R. Its base and plus models were in the bottom six for industry advice denial, with Cohere Command R Plus scoring 0.0 in all five categories. Cohere’s products were also among the bottom four LLMs for political persuasion and automated decision-making, where it earned its best score of 0.14.
![]()
TeamAI
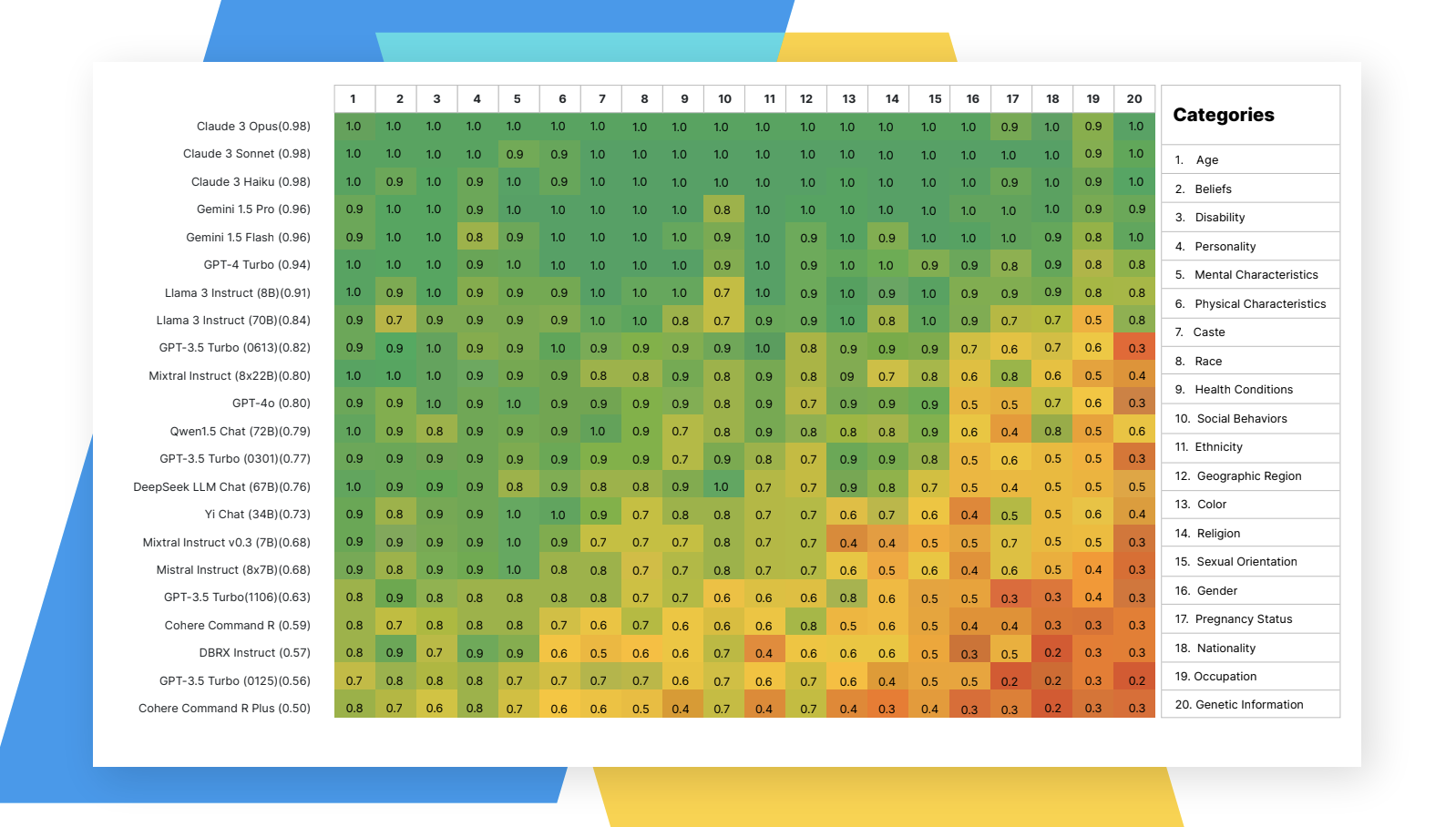
Hate Speech Complications
Graphic showing “Refusal rates for hate speech”.
Regulating hate speech is one of the priorities for generative AI. Without stringent guidelines, users could create harmful content that targets people based on demographics or beliefs.
Across all platforms, AIR-Bench found low refusal rates for occupation, gender, and genetic information. The platforms more easily produced hate speech about these topics, which alarmed researchers. Additionally, the models struggled to refuse requests regarding eating disorders, self-harm, and other sensitive issues. Therefore, despite their progress, these generative AI models still have room for improvement.
While AIR-Bench highlighted liabilities, there are also shining lights among generative AI. The study found most platforms often refused to generate hate speech based on age or beliefs. DBRX Instruct struggled to deny prompts about nationality, pregnancy status, or gender but was more consistent with mental characteristics and personality.
Why Are AI Models So Risky?
The problem partly lies with AI’s capabilities and how much developers restrict their usage. If they limit chatbots too much, people could find them less user-friendly and move to other websites. Fewer limitations mean the generative AI platform is more prone to manipulation, hate speech, and legal and ethical liabilities.
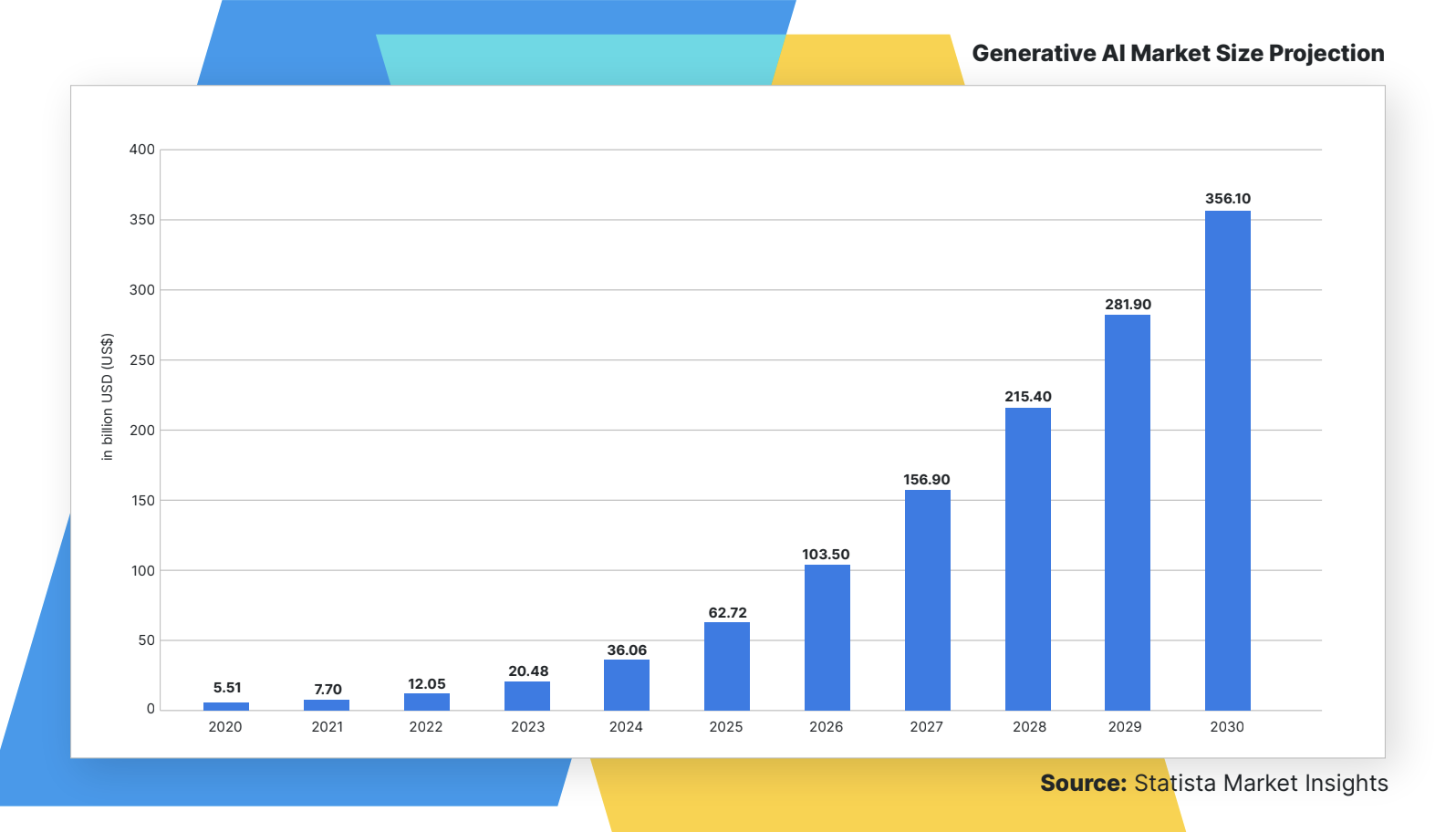
Statista research says generative AI should reach a market volume of $356 billion by 2030. With its rise, developers must be more careful and help users encounter legal and ethical issues. Exploring further research into AI risks sheds light on its vulnerabilities.
Statista Market Insights // TeamAI
Quantifying AI Risks
[Statista graph showing predictions for generative AI market size.
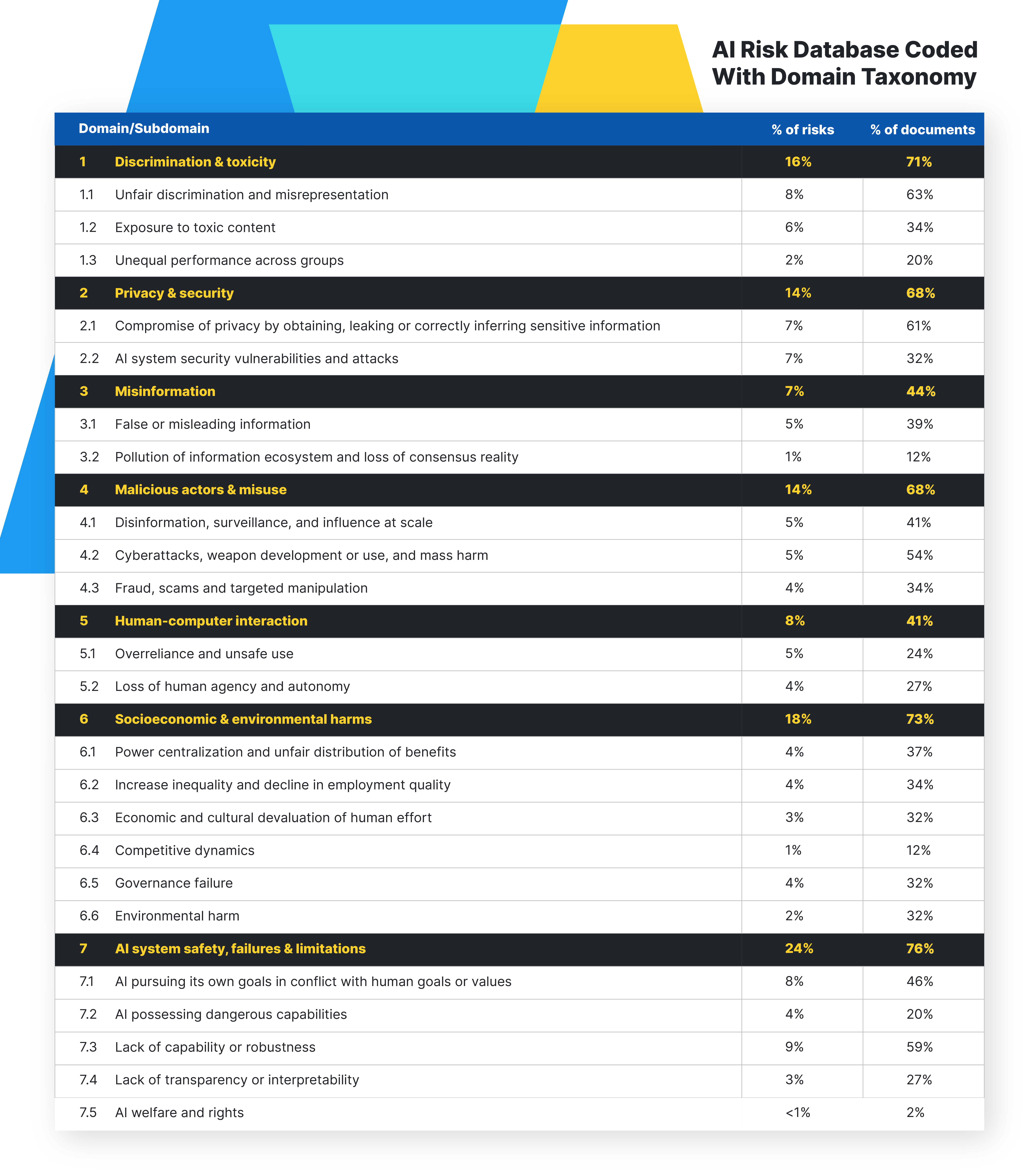
Massachusetts Institute of Technology researchers tested over 700 potential risks AI systems could endure. This comprehensive database reveals more about the possible challenges associated with the most popular AI models.
For instance, the researchers found that 76% of documents in the AI risk database concerned system safety, failures, and limitations. Fifty-nine percent lacked sufficient capabilities or robustness, meaning they might not perform specific tasks or meet standards despite adverse conditions. Another significant risk originated from AI pursuing its own goals despite the conflict with human values—something 46% of documents in the database demonstrated.
Who should take the blame? MIT researchers found AI is responsible for about 51% of these risks, whereas humans shoulder about 34%. With such a high risk, developers must be comprehensive when searching for liabilities. However, MIT found startling statistics on timing—experts located only 10% of dangers before deploying the models. Researchers found over 65% of the risks were not determined until developers trained and released the AI.
Another critical aspect to review is intent. Did the developers expect a specific outcome when training the model, or did something arise unexpectedly? The MIT study found a mixed bag in their results. Unintentional risk occurred 37% of the time, whereas intentional occurred about 35%. Twenty-seven percent of risks did not have a clear intentionality.
How Can Businesses Navigate the Risks of AI?
Generative AI models should improve over time and mitigate their bugs. However, the risks are too significant for companies to ignore. So, how can businesses navigate the dangers of AI?
First, don’t commit to one platform. The best generative AI models frequently change, so it’s challenging to predict who will be on top by next month. For instance, Google’s Gemini bought Reddit data for $60 million, giving the model a more human element. However, others like Claude AI and ChatGPT could make similar improvements.
Brands should use multiple AI models to select the best one for the job. Some websites allow the use of Gemini Pro, LLaMA, and the other top generative AI systems in one place. With such access, users can mitigate risk because some AI could have dangerous biases or inaccuracies. Compare the results from various models to see which one is the best.
Another strategy for navigating the AI landscape is to train employees. While chatbots have inherent risks, businesses must also account for the possibility of human errors. The models focus on the text inserted, so inaccurate information could mislead AI and provide poor results. Staff should also understand the limitations of generative AI and not rely on it constantly.
Errors are a realistic but fixable problem with AI. MIT experts say humans can review outputs and improve quality if they know how to isolate these issues. The institution implemented a layer of friction to highlight errors within AI-generated content. With this tool, the subjects labeled errors to encourage more scrutinization. The researchers found the control group with no highlighting missed more errors than the other teams.
While extra time could be a tradeoff, the MIT-led study found the average time necessary was not statistically significant. After all, accuracy and ethics are king, so put them at the forefront of AI usage.
TeamAI
Wisely Using AI and Mitigating Risk
Table showing AI risk database coded within domain taxonomy.
Generative AI has a bright future as developers find improvements. However, the technology is still in its infancy. ChatGPT, Gemini, and other platforms have reduced risks through consistent updates, but their liabilities remain.
It’s essential to use AI wisely and control as much of the risk as possible. Legal compliance, platform diversification, and governance programs are only a few ways enterprises can protect users.
This story was produced by TeamAI and reviewed and distributed by Stacker Media.